
ViDoRAG
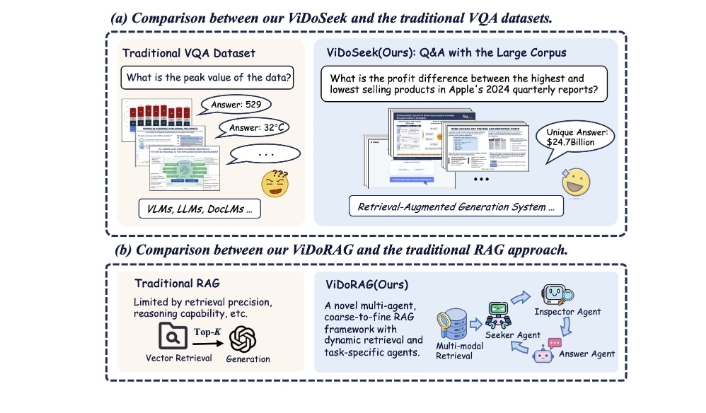
ViDoRAG是一个视觉文档检索增强生成框架,它利用动态迭代推理代理来提高生成模型的噪声鲁棒性。它基于名为ViDoSeek的数据集进行评估。ViDoSeek是一个专门为视觉丰富的文档检索、推理和回答而设计的benchmark,非常适合评估大型文档语料库中的RAG。
核心特点:
- ViDoSeek数据集: 专门设计用于评估视觉丰富文档的检索、推理和回答任务,数据集包含问题、答案和相关文档页面信息。
- ViDoRAG框架: 采用多代理、Actor-Critic范式进行迭代推理,增强了生成模型的噪声鲁棒性。
- 多模态混合检索: 基于GMM(高斯混合模型)的多模态混合检索策略,有效地整合视觉和文本管道。
使用场景:
ViDoRAG适用于需要处理大量视觉丰富文档(如PDF、扫描文档)并从中提取信息并进行推理的应用场景,例如:
- 智能文档问答: 用户可以提出关于文档内容的问题,ViDoRAG能够检索相关文档,理解内容并生成答案。
- 知识图谱构建: 从视觉文档中提取实体和关系,构建知识图谱。
- 报告分析: 分析包含图表、图像等视觉元素的报告,提取关键信息和趋势。
- 教育领域: 帮助学生理解教材中的复杂图表和图像,并解答相关问题。
总结来说,ViDoRAG通过结合视觉和文本信息,并使用多代理的迭代推理,能够更有效地理解和处理视觉文档,从而在各种信息检索和问答场景中发挥作用。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:86911638