
OpenManus-RL
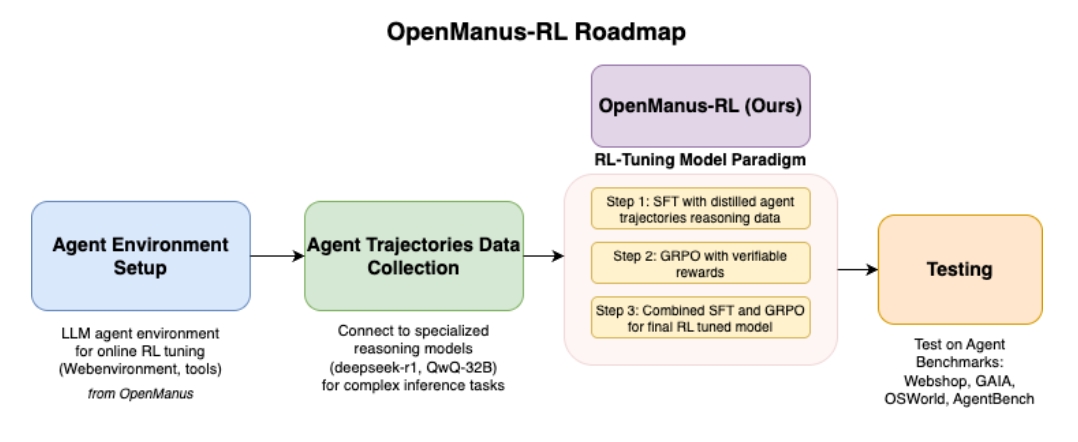
OpenManus-RL 是一个由 Ulab-UIUC 和 MetaGPT 共同领导的开源项目,旨在利用强化学习(RL)来提升大型语言模型(LLM)作为智能代理的推理和决策能力。该项目受到 Deepseek-R1 和 QwQ-32B 等成功案例的启发,探索基于 RL 的 LLM 代理调优的新范式。
主要特点和目标:
- 开源与协作: 项目秉持开放的原则,鼓励社区参与,共同推动智能代理推理和工具集成的发展。
- 动态更新: 项目进展、测试结果(基于 GAIA、AgentBench、WebShop 和 OSWorld 等代理基准测试)和调优模型将定期公开分享和更新。
- 多种推理模型探索: 项目评估 GPT-O1、Deepseek-R1 和 QwQ-32B 等多种先进的推理模型,为优化和训练策略提供信息。
- 多种 Rollout 策略: 项目尝试 Tree-of-Thoughts (ToT)、Graph-of-Thoughts (GoT)、DFSDT 和 Monte Carlo Tree Search (MCTS) 等 Rollout 策略,以提高代理规划效率和推理稳健性。
- 多样化的推理格式: 项目分析并比较 ReAct 和基于结果的推理等多种推理输出格式,以确定最有效的推理表示形式。
- 后训练策略: 项目研究 Supervised Fine-Tuning (SFT)、Generalized Reward-based Policy Optimization (GRPO)、Proximal Policy Optimization (PPO)、Direct Preference Optimization (DPO) 和 Preference-based Reward Modeling (PRM) 等后训练方法,以有效微调代理推理。
- 奖励模型训练: 项目使用带注释的数据训练专门的代理奖励模型,以准确量化细微的奖励信号。
- 测试时轨迹缩放: 在推理阶段,实施轨迹缩放方法,使代理能够灵活地适应不同的任务复杂性。
- 行动空间意识和战略探索: 为代理配备行动空间意识,并采用旨在有效导航复杂行动空间的系统探索策略。
- 与 RL 调优框架集成: 项目集成了 Verl、TinyZero、OpenR1 和 Trlx 等领先 RL 调优框架的见解和方法。
- **工具使用:**项目旨在提升LLM对工具的使用能力。
项目包含代码和数据集,并提供简化的SFT和GRPO的实现
简而言之,OpenManus-RL 旨在通过结合先进的推理范式、多样化的 Rollout 策略、精细的奖励建模和强大的 RL 框架,显著提升 LLM 代理的推理能力和适应性。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:86911638