
HumanOmni
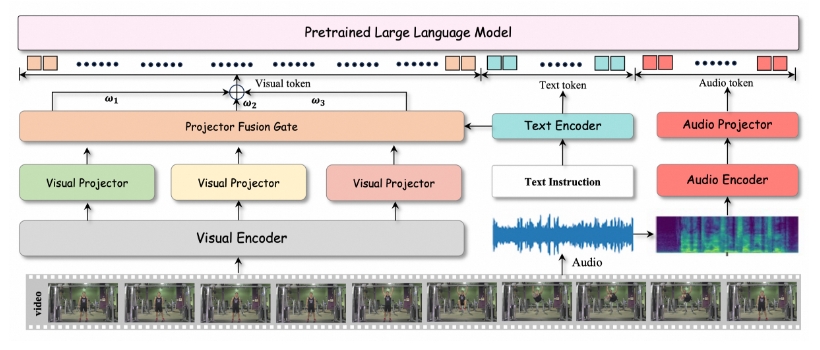
HumanOmni 是一个以人为中心的 Omni 多模态大型语言模型,旨在全面理解以人为中心的场景。它具备以下关键特点:
- 大规模数据集: 基于 240 万个人物视频片段,包含 1400 多万条指令,以及 5 万个视频片段和超过 10 万条人工标注指令,涵盖情感识别、面部描述和特定说话人的语音识别等。
- 人脸、身体、交互分支: 采用三个分支分别处理人脸、身体和交互相关的场景,并根据输入指令动态调整融合权重,以确保在各种场景中都能做出准确响应。
- 音视频协同: 能够同时理解视觉和语音信息,从而更全面地理解复杂场景。
- 性能优越: 在情感理解和动态面部表情描述等任务上表现优于其他模型。
HumanOmni 的使用场景:
- 视频内容理解: 可以用于理解和分析视频中的人物行为、情感和交互,例如识别视频中人物的情绪,分析他们的行为和意图,或者理解他们之间的关系。
- 智能监控: 可以应用于智能监控系统,用于检测异常行为,识别特定人物,或者分析人群的情绪状态。
- 人机交互: 可以用于改善人机交互体验,例如让机器人能够更好地理解人类的情绪和意图,从而做出更自然和智能的反应。
- 情感分析: 它可以用于分析电影,电视剧或者综艺节目里人物的情感,理解人物行为背后的原因。
- 虚拟现实和增强现实: 为虚拟角色提供更逼真的行为和情感表达,从而增强沉浸感。
总而言之,HumanOmni 能够理解人类的音视频信息,适合在各种需要理解和分析人类行为、情感和交互的场景中使用。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:86911638