
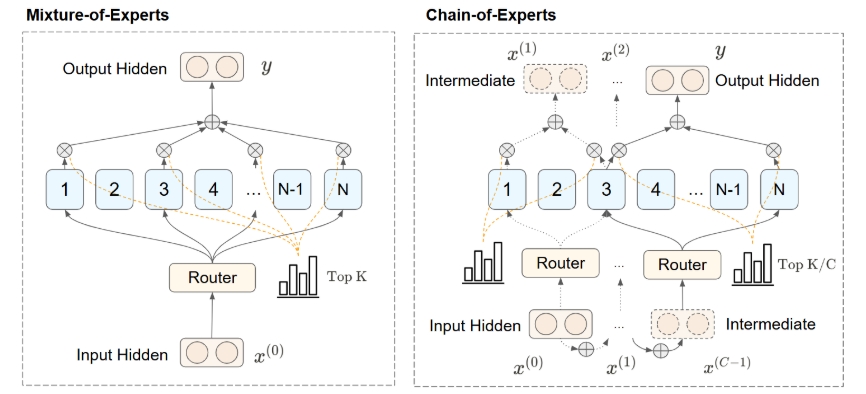
CoE
CoE (Chain-of-Experts) 是一种新颖的稀疏大型语言模型 (LLM) 处理方法,它通过在 Mixture-of-Experts (MoE) 模型中的层内专家之间实施顺序通信来改变了传统的处理方式。
核心思想:
- 顺序通信: CoE 引入了一种迭代机制,使专家能够通过处理来自其他专家的输出来进行“通信”。这与传统的 MoE 模型中专家之间并行且独立的信息处理方式不同。
- 专家链: 顾名思义,通过迭代让 Token 顺序地经过不同的专家,形成一个专家链。
优势:
- 性能提升: 在数学验证任务中,两次迭代的 CoE 显著优于传统的 MoE 模型。
- 更好的扩展性: CoE 两次迭代的性能与三次专家选择的性能相匹配,优于层缩放。
- 内存效率: 在性能相当的情况下,CoE 的内存使用量降低了 17.6%。
- 灵活性: 专家组合的可能性增加了 823 倍,提高了利用率、通信和专业化程度。
关键特性:
- 独立的门控机制: 增强模型性能,并解释专家专业化。
- 残差连接: 内部残差连接比外部残差连接更有效,意味着顺序处理可以提升模型的有效深度,使得每一个专家能更好地学习残差。
“免费午餐” 效应:
CoE 提供了一种 “免费午餐” 加速效果,通过重构信息在模型中的流动方式,在计算开销更少的情况下实现了比以前的 MoE 方法更好的结果。这可能是由于以下三个因素造成的:
- 更多的专家选择自由度。
- **统一了顺序处理和专家通信的概念:**不同的专家可以依次处理,从而增加了 Transformer 的有效深度;一个专家在迭代过程中有机会多次处理一个 token,从而有助于促进专家专业化。
总之,CoE 通过实现稀疏神经网络中的通信处理,解决了当前 MoE 架构中的基本限制,同时以更低的计算需求提供卓越的性能,有望成为一种高效且有效的 LLM 扩展方法。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:86911638