
Step-Audio
Step-Audio简介
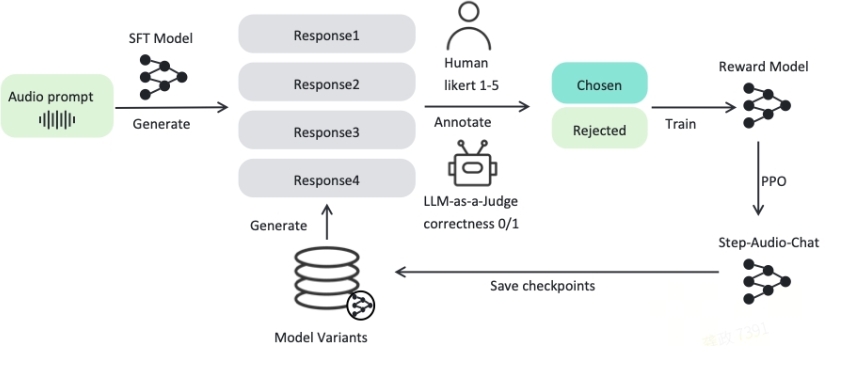
Step-Audio是一个创新的开源框架,专为智能语音交互而设计。该框架整合了理解和生成能力,支持多语言对话(如中文、英语和日语)、情感表达(如喜悦和悲伤)、地方方言(如粤语和四川话)、可调节的语速以及多样的韵律风格(如说唱)。Step-Audio的主要技术创新包括:
- 130B参数的多模态模型:该模型能同时实现语音识别、语义理解、对话、语音克隆和语音合成的功能。
- 生成数据引擎:减少了传统文本转语音(TTS)对手动数据采集的依赖,通过生成高质量音频来训练资源效率高的TTS模型。
- 细粒度语音控制:提供精细的控制选项,包括情感(如愤怒、喜悦)和声调(如说唱)等,以满足不同语音生成需求。
- 增强智能:通过集成工具调用机制和角色扮演增强代理在复杂任务中的表现。
使用场景
Step-Audio在多个领域中具有广泛的应用潜力,包括但不限于:
- 智能音箱和语音助手:提供自然流畅的对话体验,支持多种语言和情感表达。
- 客服机器人:通过情感控制和语音克隆,提供更人性化的客户服务体验。
- 教育和培训:在语言学习或其他教育场景中,以多种风格和情感辅助学习。
- 娱乐和游戏:为游戏角色提供高质量的配音,增强沉浸感并提升用户体验。
- 语音创作:帮助音频创作者快速生成有趣的语音内容,如说唱和戏剧表现。
Step-Audio的多样化功能可以适用于任何需要智能语音处理和交互的场景,极大地提升用户体验和交互质量。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:86911638